
Protect sensitive data with a neutral AI system security policy
Custom GPT and Assistant API mastery for tech leaders.


I broke down the architectural issues from this post in a YouTube video, if interested.
TL;DR
OpenAI has launched a new set of products called GPTs (generative pre-trained transformers) that allow for no-code AI agent development.
These introduce a potential security concern (among others): allowing direct user access to the underlying knowledge base.
Use the “Assistant” application programming interface (API) to apply a layer of business logic checks and only provide sensitive information to specific, authenticated individuals or groups thereof. This requires development outside of OpenAI’s tools, but is more secure.
OpenAI’s dizzying pace of product launches
People in the tech world talk a lot about rocket ships.
OpenAI is proving to be one.
Its pace of product development has been nothing short of amazing over the past year, with its early November 2023 announcements being the most recent in an impressive array.
Buzziest among them was their launch of GPTs, essentially a no-code tool for building custom AI agents (check out StackAware’s SOC 2 advisor here). And GPTs leverage a major improvement to the existing OpenAI API: the addition of the “Assistant” feature. Both approaches allow developers to provide custom (and potentially proprietary) knowledge bases to the core GPT-4 model, so that configuring retrieval-augmented generation (RAG) is much easier than it had been previously.
New products mean new potential security gaps
Predictably, people began demonstrating the potential security pitfalls of GPTs. Specifically, Itamar Golan (a StackAware business partner) and Antoni Rosinol demonstrated the ability to directly access and in some cases - download - these custom knowledge bases.

These situations demonstrate why defining business and security requirements is so important.
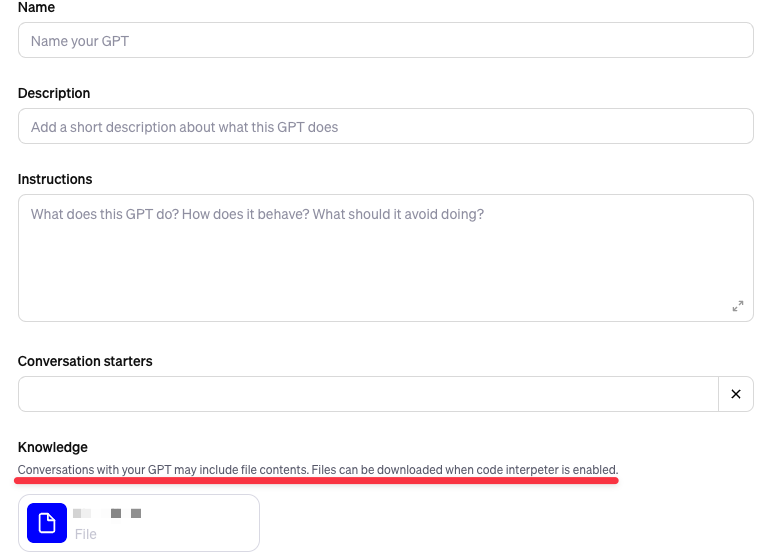
That’s because it’s frankly not clear to me whether the ability to download the entire knowledge base is a bug or a feature. (Update: 19 November 2023) I think it’s a toss-up, but I lean toward the latter because this specific behavior appears to be documented (somewhat cryptically) in the GPT builder user interface:
AI applications demand a neutral security policy
Golan’s and Rosinol’s observations are nevertheless important because people would likely have otherwise ignored this potential GPT “feature” and begun unintentionally exposing sensitive information to their users. This is because it seems many are under the impression that Large Language Models (LLM) or AI models more generally should themselves serve as an authorization layer on top of existing data.
They should not, because doing so creates a tainted trust boundary.1
Instead, AI models should follow a “neutral” security policy, whereby a user who can access a given instance of a model should also be authorized to access the underlying context.2 This doesn’t necessarily mean you give everyone with access to the model access to the entire corpus. You can still apply rate limits and/or context window constraints to prevent the wholesale extraction of it. A neutral security policy just means that you wouldn’t consider it a breach if an interaction with a model revealed a piece or several pieces of the model’s context.
In any case, unfortunately, the current GPT feature set only gives you a one-size-fits-all approach whereby there is no way to restrict access to the knowledge base on an individual user level.3
(Update: 19 November 2023) After a good LinkedIn discussion with Robert Shala on the topic, I revisited my original assessment and view this situation as to be so vague that it’s basically unintelligible as to whether or not a user should be able to download a GPT knowledge base. A very literal interpretation of the documentation, e.g. that responses to users “may include file contents” and that “files can be downloaded” would suggest this is in fact desired behavior.
With that said, Robert suggests OpenAI itself did NOT envision a neutral security policy for GPTs due to the custom instructions that he appears to have extracted (hilariously enough, via his own prompt injection, which is a separate but also serious issue):

Combined with the fact that OpenAI’s marketing for GPTs stated an appropriate use case for them was in fact using “proprietary” data, there is - at a minimum - major internal confusion within the company as to applicable security requirements.

It looks like the answer to the question “should users be able to download GPT knowledge bases” could vary depending on which department at OpenAI you ask:
Marketing: no
(Prompt) Engineering: no
Documentation / User Experience: yes
(Update: 1 December 2023): OpenAI issued an email clarification that the downloading of knowledge base files is in fact a feature which is now off by default. They also promised “added messaging to better explain this” but I was not able to find such messaging, even after asking LinkedIn.

How to build a custom assistant and protect your knowledge base with Threads
The good news is that the Assistant API does let you implement a neutral security policy via the Threads feature. Unlike GPTs, you can choose whether to pass a file at the Assistant-level (i.e. make it available to all users) or the Thread level (i.e. make only available to a specific user).
Thus, you can build out separate logic in your application that only makes certain information available to certain users. For example, if you were building a customer support bot, you could authenticate your user through your normal method and then pass only that user’s information to a specific Thread. You could also build logic that injects certain types of information (such as different types of knowledge bases with different data classifications) into Threads for certain users based on their membership to a certain group (e.g. administrators, paying customers, freemium customers, etc.).
This is far better than providing custom instructions to a GPT like “only provide a user a file if he can prove his identity,” which is basically guaranteed to fail. While it does require development (no-, low-, or full-code) to implement, the security benefit is absolutely worth it if you have any concerns about your knowledge base’s sensitivity. If you are merely structuring publicly-available data and providing it to a GPT (as I did with the SOC 2 advisor), these additional steps are unnecessary.
Be mindful of data retention when using Assistants
Helpfully, you can delete files uploaded to an Assistant or Thread. You almost certainly will want to do this if you are ever passing anything sensitive to be used in a given conversation. It’s also important to note
that deleting an
AssistantFiledoesn’t delete the original File object, it simply deletes the association between that File and the Assistant. To delete a File, use the File delete endpoint instead.
So make sure you don’t just delete the association and forget about the original file, letting it hang around.
Additionally, I wasn’t perfectly clear as to how OpenAI retains uploaded files. API inputs are stored for 30 days (barring a legal hold), so I reached out to determine if and how that policy applied to uploaded files. I’ll update this post if I learn anything.

(Update: 15 December 2023) OpenAI sent me an email saying there is no retention of files deleted using the API endpoint:

OpenAI should unify GPT and Assistant API management
The biggest feature gap I see here is that, while on the back-end it looks like GPTs and Assistants leverage the exact same infrastructure and logic, they cannot be used interchangeably. If you are going to build a GPT via the user interface (UI), you need to keep using the UI. And if you are building an Assistant via the API, you need to keep doing it that way.
I recommend OpenAI integrate GPT and Assistant functionality so users can start building custom AI agents without dealing with the API but can integrate it later if needed. For quick changes for non-sensitive information, a developer should be able to easily update the knowledge base via the UI. But they should also be able to create custom business logic using their own app that allows for selective uploading (and subsequent deleting) of sensitive information for specific user conversations (via Threads).
In the meantime, OpenAI should absolutely clarify GPT documentation to make it clear builders should develop their apps with a neutral security policy, i.e. not relying on the AI model to moderate access to the underlying data (Update 19 November 2023) And OpenAI should stop relying on this flawed mechanism itself.
Is your head spinning with the speed of AI’s advance?
It took only a few days for misunderstandings about GPT security to result in some potential leakages of sensitive data. And these are just a few of the instances we know about.
With the rapid advancement of artificial intelligence over the past year, having a trusted partner who can help you meet your:
Cybersecurity
Compliance
Privacy
requirements is a must.
Ready to see how StackAware can help?
Thanks to Jonathan Todd of valhall.ai for introducing me to this term.
I paraphrased this definition from a Cybersecurity and Infrastructure Security Agency (CISA) post. Although I’ve been critical of many of their statements on security, I give credit where it is due.
Turning off the code interpreter may prevent bulk downloading of files, but it still doesn’t prevent directly revealing knowledge base information via conversation with the GPT. And enabling the code interpreter might be necessary for your use case.