
Deploy Securely with GitHub Copilot
Mitigating insecure code generation, unintended training, and more.


TL;DR
Apply special scrutiny, from an application security perspective, to GitHub Copilot-developed code.
Disable “Allow GitHub to use my code snippets for product improvements.”
If your organization has sufficient economic leverage, consider asking GitHub to formally define Telemetry and Code Snippets in the context of Copilot, as well as inquiring as to how it monitors for abuse and improves prompt crafting via User Engagement Data (and send me the response if you get one!).
Set “Suggestions matching public code” to “Block.”
Intro
AI Copilot use is exploding throughout the enterprise. One of the first places it took hold was in accelerating development by auto-completing existing code and generating new functionality through natural language prompting.
As with any new technology, though, there are risks. I view the top 3 as being:
Insecure code and configuration generation
Data leakage through unintended training
Copyright infringement
GitHub Copilot now offers six plans:
Free
Pro
Pro+
Max for individual developers
Business (for organizations)
Enterprise (for organizations)
These have different price points, and unsurprisingly, different data retention and AI training policies. I pieced together the GitHub documentation, which is far from consolidated, to put together this article. My recommended mitigations are above and my analysis of the risks is below.
Insecure code and configuration generation
Generating buggy code or bad security configurations is the top risk of using Copilot. According to one paper (admittedly from late 2021, so things have likely improved), up to 40% of Copilot’s recommendations included security vulnerabilities. Another more recent one suggests, all other things being equal, those using AI coding assistants write less secure code but are more confident about its security.
That’s probably because the training data includes a huge number of vulnerabilities!
Similarly, Amazon’s recently-released Q is reportedly providing incorrect security recommendations. AWS already has a lot of issues with misconfigurations, so an AI model trained on common worst practices is likely to reproduce them.
And the above analysis doesn’t even include the possibility of the model hallucinating flawed code or incorrect recommendations. This represents additional risk on top of GitHub Copilot being trained on bad data.
So definitely pay close attention to AI-generated outputs. Consider adding a third human reviewer (hopefully you already have one person who didn’t generate a pull request check it) for anything containing Copilot suggestions. The whole point of Copilot is to help you save time so you should have some capacity available to do a more thorough security review.
Data leakage through unintended training
Especially when it comes to proprietary code, protecting its confidentiality is a big deal. It looks like Samsung got burned by unintended training earlier this year when an employee submitted some code to ChatGPT (presumably in its default training mode).
Separately, it’s possible that if your developers accidentally hard-code credentials (application programming interface (API) keys, etc.), these could be reproduced by GitHub Copilot for other users. Although this appears to be rare, this could result in:
Additional risk of lost data confidentiality, integrity, and availability due to malicious activity.
Huge cloud service provider bills due to accidental usage of your API key by other Copilot customers.
So I would suspect most companies would be quite concerned about how vendors handle their code.
Unfortunately, I had a hard time understanding how exactly Copilot does this. GitHub uses (at least) 5 different terms to describe the various types of information it processes, and some of these are not clearly defined. Below I do my best to patch together their meanings.
Code snippets
This term is used throughout the documentation but I could never find an actual definition of it. Does it refer to:
Your existing code stored in GitHub?
Selections of it? If so, how much?
Anything else?
At a minimum, it appears both Prompts and Suggestions (discussed below) are covered:
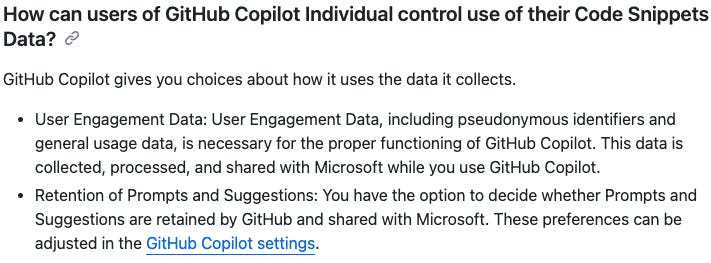
When you go to the GitHub Copilot settings, though, there is no mention of Prompts and Suggestions, only Code Snippets:
This FAQ also implies that direct matches of your Code Snippets will not be shared as Suggestions to others, but it certainly seems that outputs from models trained on your code could be provided to other users. As long as there isn’t a perfect match, it seems like it’s fair game.

Overall the definition of and processing policies for Code Snippets is very fuzzy to me.
Prompts and Suggestions
These are pretty clear.
Prompts include “code and supporting contextual information that the GitHub Copilot extension sends to GitHub to generate suggestions.”
Suggestions are “one or more lines of proposed code and other output returned to the Copilot extension after a prompt is received and processed by the AI models that power Copilot”
Retention and training: GitHub Individual (Free, Pro, Pro+)
As of April 2026, GitHub updated its privacy policy to allow use of individual users’ Copilot interaction data - including inputs, accepted outputs, and code context - for model training. This is opt-in and can be disabled at any time in account settings. Business and Enterprise customers remain excluded from training data collection by contract.

Retention and training: GitHub Business
According to Copilot’s product-specific terms:
Prompts are transmitted only to generate Suggestions in real-time and are deleted once Suggestions are generated. Prompts are not used for any other purpose, including the training of language models.
Telemetry
I could not find a clear definition of this anywhere, but Telemetry appears to be synonymous with Code Snippets:

This chart discusses “Telemetry” without defining it.
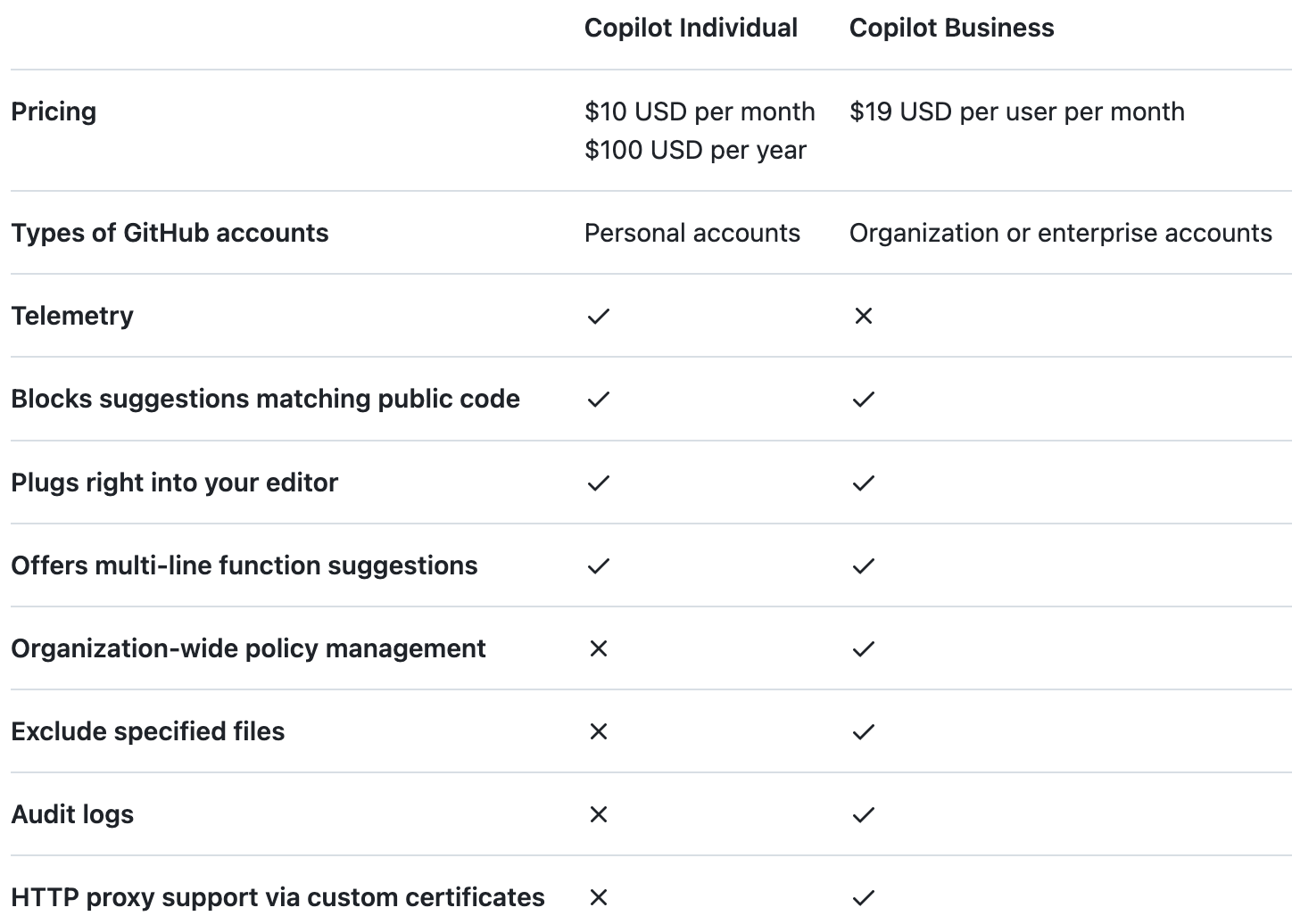
Retention and training
The above graphic seems to imply that Individual users cannot opt-out of Telemetry. Assuming telemetry includes prompts and suggestions, then this appears to have at one time been the case according to at least one Hacker News user. But it is definitely possible to opt-out of Code Snippet sharing (presuming it is the same as Telemetry) as of this post’s publication date.
Perhaps there is some other type of Telemetry captured, from which Individual users cannot opt-out. But what that is is not clear.
Business users don’t appear to have Telemetry collected or processed.
User Engagement Data
This is defined as:
information about events generated when interacting with a code editor. These events include user edit actions (for example completions accepted and dismissed), error messages, and general usage data to identify user metrics such as latency and feature engagement. This information may include personal data, such as pseudonymous identifiers.
Here are some uses of the data:

I am not clear how User Engagement Data could be used for abuse monitoring or prompt crafting unless it included…Prompts. It seems to me that User Engagement Data would only include which buttons get clicked or when, as well as any error messages returned.
Amazon Bedrock, for example, does perform abuse monitoring of prompts. But it does so in a stateless fashion, not storing the prompts themselves. Only the pass/fail results from the classifier are retained.
Copyright infringement
I am not a lawyer and this is not legal advice.
If you’ve been living under a rock, you might have missed the fact that a massive series of battles have been fought over alleged copyright infringement by generative AI model providers. The class-action lawsuit against GitHub reached a resolution in May 2026 - a jury returned a unanimous defense verdict, and the case was dismissed.
What I call the “apocalypse” scenario - a court ruling that any Copilot-generated code infringes on all code it was trained on - did not materialize. The litigation largely resolved in GitHub’s favor. That said, the indemnification question remains worth understanding.
I think there are some interesting discussions from a legal perspective, but since that’s not my area of expertise, I’ll speak to the business and technical side of things.
Ultimately, I think this issue will get effectively settled by the indemnification provisions the generative AI providers are offering. Basically, Microsoft (and a rapidly expanding array of companies) have agreed to defend certain customers using certain products under certain conditions.
Specifically, in the context of its Copilot products, Microsoft has committed that “if you are challenged on copyright grounds, we will assume responsibility for the potential legal risks involved.”
It’s probably not a valuable use of resources for any company to go toe-to-toe with Microsoft’s legal team. I’m not weighing in on whether Microsoft is right or wrong, I’m just talking economics.
Definitely consult with counsel before relying on the indemnity (or doing anything I discuss in this section). But on a technical level, there is a key step to take to ensure coverage under Microsoft’s policy, should you choose to do so. According to Copilot’s product-specific terms,
any GitHub defense obligations related to your use of GitHub Copilot do not apply if you have not set the Duplicate Detection filtering feature available in GitHub Copilot to its “Block” setting.
So make sure you enable this. Here is what it looks like on the settings screen:

Reminder: I am not a lawyer and this is not legal advice.
Ready to take action?
Mapping out all of this - just for GitHub Copilot alone - took a huge amount of time and effort. And I spend a lot of my day analyzing terms of service for AI training and data retention provisions!
I’m guessing that you don’t have the time to do this yourself. And I’m also guessing your product and engineering teams are aggressively moving ahead with deploying AI tools like Copilot.
So if you need help in mapping and managing your artificial intelligence-related risk, let us know.
It’s what we do.
Great insights and also very awakening points. The risks of using Copilot at free will without really understanding how things work underneath the covers could put many companies in trouble reputational or legally.