
Exploit Prediction Scoring System (EPSS): a deep dive
A generally good tool for evaluating CVE exploitability.


Despite reputable organizations warning (admittedly in a self-interested way) against it, many security teams focus robotically on fixing “high and critical” vulnerabilities in their networks. An inherent problem of such qualitative language is its imprecision, but I interpret such references to “highs and criticals” as meaning “having a Common Vulnerability Scoring System (CVSS) rating of 7.0 or greater as recorded in the Common Vulnerabilities and Exposures (CVE) list or National Vulnerability Database (NVD).”
There is evidence, unfortunately, that such prioritization methods are no more effective - from a risk management perspective - than randomly picking issues to remediate.
I view this as being a result of two separate but related problems:
CVSS is not an appropriate tool for risk management, but has become the industry standard nonetheless. See this post for details, but suffice to say, I don’t think that the CVSS formula is an effective tool for measuring the severity of a potential vulnerability, let alone serving as a good way to measure risk (which, if you recall is a combination of both the severity of an incident and its likelihood of occurrence).
As a separate problem from the design of the CVSS, the scores of CVEs as recorded in the CVE list/NVD are rarely reflective of the true CVSS rating of a given issue when evaluated in its full context. This is especially relevant to cybersecurity practitioners when scrutinizing 3rd (and greater) party software dependencies contained in their technology stack. I have also done a deep dive on this problem, but to summarize, taking the NVD CVSS rating for given component at face value is likely to be misleading a majority of the time.
It bears repeating that I have nothing against the Forum of Incident Response and Security Teams (FIRST), which maintains the CVSS standard…they seem like good people and have responded rapidly and helpfully to my inquiries for this article. Additionally, I think it’s important to note that FIRST itself partially agrees with both of my above characterizations.
The good folks at FIRST have thus developed another metric that is far more relevant to cybersecurity risk management: the Exploit Prediction Scoring System (EPSS). Earlier this month, FIRST updated the EPSS, and in this post I will review the system and make recommendations for its implementation. In general, the EPSS looks to be a solid tool for vulnerability prioritization efforts, especially given its price (free). While I have some caveats, overall its introduction is a step in the right direction and a win for cybersecurity practitioners.
Overview
In their own words, FIRST describes EPSS as:
an open, data-driven effort for estimating the likelihood (probability) that a software vulnerabilit[y] will be exploited in the wild…it uses current threat information from CVE and real-world exploit data. The EPSS model produces a probability score between 0 and 1 (0 and 100%). The higher the score, the greater the probability that a vulnerability will be exploited.
After clarifying directly with FIRST, they confirmed to me that the relevant time period for when such a vulnerability will be exploited is “the next 30 days,” implying it is continuously updated and adjusted based on changing conditions.
From a practical perspective, this is crucial information. If you identify a severe vulnerability in your network, you might rightly be tempted to drop everything to resolve it immediately, irrespective of the costs involved. If the odds of it being exploited, however, are extremely low, you might reasonably defer fixing it, potentially indefinitely if the EPSS score is sufficiently low.
Turning to the specifics of the model, there is a lot of discussion of statistics and machine learning terminology, along with many caveats which I will omit in my discussion here, but I’ll give a quick preamble with what I think to be the most important points.
Foremost, it’s important to note that the EPSS is an entirely correlative-based model. It analyzes historical events and then makes predictions about future ones. It cannot necessarily tell you why anything happened - e.g. why a certain vulnerability was exploited - and frankly, that’s fine from the narrow perspective of Deploying Securely.
There is much discussion about whether data science (of which machine learning is a component) is really “science.” For the most part, I don’t think it is, because the vast majority of the field does not use the scientific method: testing a hypothesis via a control and experimental group. Without such experimentation it is not possible to determine causality with any degree of certainty.
Here’s the thing, though: business leaders don’t generally care about causality - as long as the model “works” - and that’s fine! While I certainly have a philosophical desire to know why certain things - e.g. vulnerability exploitations - happen, and this knowledge can drive future innovation, I can content myself with knowing whether they will happen for the purposes of this blog. Deploying Securely is about practical application, and I’ll leave deeper thoughts to research scientists.
Turning back to the model, FIRST coins two terms - “efficiency” and “coverage” - which I think are very important for security professionals concerned about applying scarce engineering resources in a way that generates the highest return-on-investment (which should be all of them).
Efficiency considers how…resources were spent by measuring the percent of remediated vulnerabilities that were exploited…[r]emediating mostly exploited vulnerabilities would be a high efficiency rating…while remediating perhaps random or mostly non-exploited vulnerabilities would result in a low efficiency rating.
Coverage is the percent of exploited vulnerabilities that were remediated…Having low coverage indicates that not many of the exploited vulnerabilities were remediated with the given strategy.
Thus, a good model would seek to optimize for both efficiency and coverage, leading to the maximum risk reduction for the minimum cost. It’s important to provide an “all other things being equal” caveat to this statement, because the damage caused by a successful exploitation can vary widely between organizations
So, how does the EPSS fare when considering these two metrics?
According to FIRST’s graphic, pretty well when compared to the CVSS!
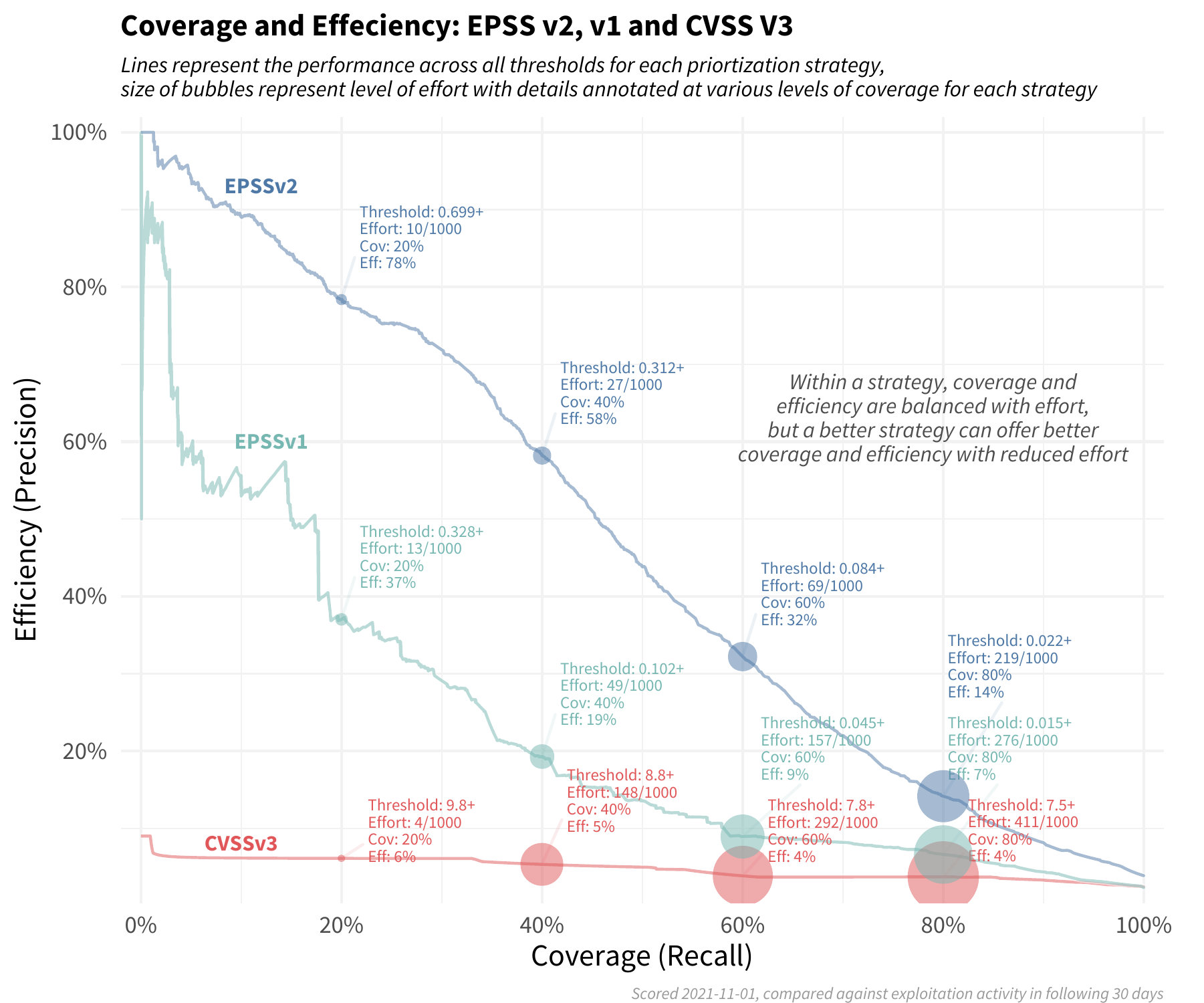
If the above chart is too complex, I think the key takeaway is here:
Using EPSS v2 requires organizations to patch fewer than 20%…of the vulnerabilities they would have mitigated, compared to using [a] strategy based on CVSS.
This is a huge amount of effort saved! In my personal experience, security-related code maintenance can consume 5-10% of an organization’s entire engineering capacity. Thus, a savings of 4-8% (80% of 5-10%) can translate into hundreds of thousands of dollars (assuming an engineering budget in the millions) a year. That is real money which can be applied to a) other, more effective security controls, b) new feature development, c) lower prices, or d) returned to investors. All-in-all, this is a huge amount of value delivered.
Model inputs
Getting into the weeds of the EPSS, I’ll review its various inputs. The contributions of each variable to the overall score can shift from one vulnerability to the next, making it impossible to create a “formula.” This is inherent to the nature of machine learning models, but the below chart (also from FIRST) gives a general idea of how much specific variables contribute to the overall score.

Each of the above items on the y-axis fit into one of nine categories (corresponding to the different colors) of inputs, which I will review individually.
MITRE’s CVE List
The starting point for analysis is the list of published CVEs, meaning publicly identified vulnerabilities only. This makes sense, in that an open source model can be expected to only take advantage of publicly available data. With that said, the fact that the EPSS only addresses published CVEs means that there is a major gap in its coverage. Since most exploitations are of previously unidentified (or at least, unpatchable) vulnerabilities, and not even all known vulnerabilities are published in the CVE list/NVD, the EPSS (as it currently exists) is only applicable to a minority of the risk surface presented by all software flaws.
Text-based tags in the CVE description and other sources
The EPSS analyzes keywords associated with each CVE to make predictions regarding how likely an attacker is to take advantage of it. Diving into the details, this factor initially seems to conflate vulnerability severity and likelihood of exploitation, one of my original critiques of CVSS. Specifically for the EPSS, though, this isn’t necessarily wrong, as I discuss below, but it’s important to note.
Severity: the keyword “denial of service” (DoS), for example, implies something about the damage an attacker can do to a network, but not necessarily anything about the likelihood of this attack happening. I could potentially achieve the same denial of service against a target by either exploiting a software vulnerability or by physically cutting the power lines to the data center running it, but these outcomes have vastly different likelihoods of occurring. Now, it’s possible, and the model appears to bear this out, that the potential severity of an attack might drive the likelihood of it occurring. DoS attacks might be easier to conduct, all other things being equal, and thus attackers will thus attempt them more often.
Likelihood: terms such as “remote” imply that it is possible to exploit a vulnerability over the internet, rather than through a physical vector. In contrast to the above example, this term says nothing about the damage an attacker can do through this vector. The mere ease by which a hacker can exploit a vulnerability, though, almost certainly drives the likelihood of him doing so, and thus such terms are also an appropriate factor to incorporate into a model.
Keywords associated with a CVE thus appear to have some predictive power with regard to whether it will be exploited or not. The exact causal relationship is unknown (and unknowable without conducting a controlled experiment), but as I mentioned, the why is less important than the what in most cases.
Days since CVE publication
This makes perfect sense, as the more time passes after publication of vulnerability, the more likely it is to be exploited. Although I haven’t done an analysis to confirm this is true in the EPSS, I would expect that the relationship between CVE age and likelihood of exploitation is highly non-linear. Very roughly speaking and according to Mandiant, of all known vulnerabilities that are exploited, 1/3 are exploited in the first week of identification, 1/3 are exploited in the subsequent month (but excluding the first week), and the remaining 1/3 are exploited after one month of identification. Thus, there is a huge drop-off in likelihood of exploitation after one month. Perhaps I’ll compare this data to the EPSS’ predictions as part of a future project (or - if you are interested in serving as a guest writer - do it yourself and send the results my way!). In any case, this is another reasonable input.
CVE reference count
After confirming with FIRST, I determined that this metric refers to the number of entries in the “References” section of a CVE’s entry (example for CVE-2021-44228 a.k.a. “log4shell” below).
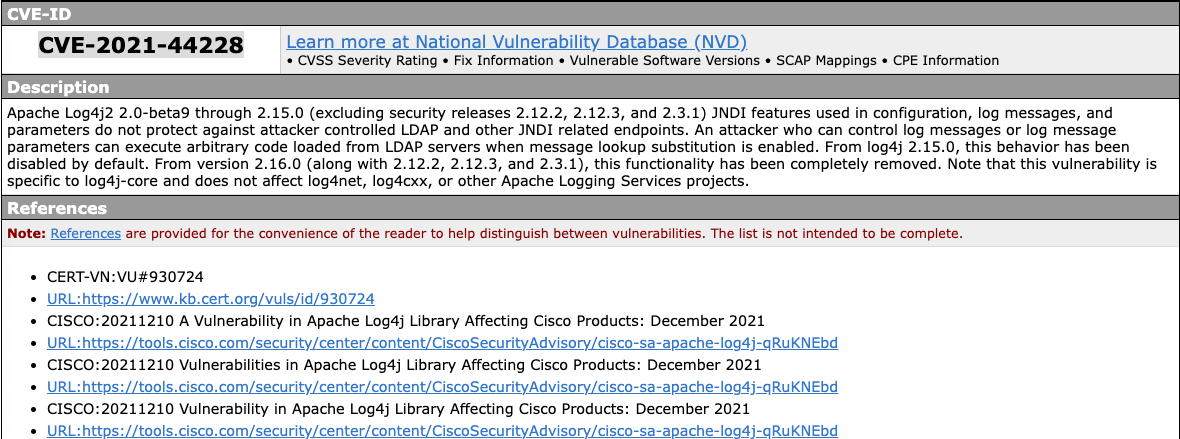
I view this factor as a proxy for the general “level of awareness” for a given vulnerability. It makes sense that a well-publicized issue would get relatively more hacker attention, and at the same time, a high risk vulnerability would get more publicity. Disentangling these two inputs is impossible given the nature of the model, but from an applied cybersecurity perspective, doing so isn’t necessary; all that matters is the likelihood of exploitation.
Existence of published exploit code in Metasploit, ExploitDB, or Github
This is another pretty obvious input (which is also confusingly incorporated into the temporal score of the CVSS). While CVSS claims to represent vulnerability severity, rather than the resultant risk, including this factor is confusing because the severity of an attack has little to do with the (non-)availability of exploit code to conduct it (with one possible exception being that a “juicer” vulnerability will likely drive more rapid development of exploit code). Furthermore, even assuming you are ignoring FIRST’s guidance and using CVSS for risk management purposes, the numerical impact of exploit availability has a relatively (and inappropriately, in my opinion) small impact on the overall rating (changing it by at most 0.5 out of the total 10 points). Unfortunately, it is logical that if there is a pre-written exploit for a given vulnerability, it’s much more likely to be exploited than if a hacker needs to write one from scratch himself. Thus, I’m happy to see this incorporated into the EPSS.
Presence of relevant CVE modules in the open-source scanners Jaeles, Intrigue, Nuclei, or sn1per
Following some dialog with the FIRST team, I learned that the EPSS model pulls daily from web scrapers monitoring the aforementioned open source tools, looking for new scanning modules targeting a given CVE. Since the above tools are meant for attack surface mapping and are all publicly available, I’ll infer that they see both malicious and legitimate use. Thus, if a new module targeting a given CVE shows up in a tool, it is more likely that it will be appear the radar of a potential attacker, leading the underlying CVE to be more likely to be exploited.
CVSS v3 vectors in the base score (not the score or any subscores) as published in the National Vulnerability Database (NVD)
This issue also required some clarification from FIRST, but after corresponding with them I determined that this input refers to the entire CVSS 3.1 vector string (e.g. CVSS:3.1/AV:N/AC:L/PR:N/UI:N/S:C/C:H/I:H/A:H). Thus, factors such as the potential attack vector and complexity, privileges required to execute, requirement for user interaction, and possible impacts to confidentiality, integrity, and availability are all included in the EPSS. While this string doesn’t explicitly include the numerical score, it does include all of the components that help calculate it. Similarly to the other model inputs, this one includes both severity and likelihood measurements.
CPE (vendor) information as published in NVD
This is very interesting, as it suggests (correctly in my view), that some vendors are more likely to be exploited than others, all other things being equal. This makes sense, in that companies whose products and services are ubiquitous - e.g. Microsoft - have a larger total attack surface.
Observations of exploitation-in-the-wild from AlienVault and Fortinet
Another very reasonable input here. Observation of a vulnerability actually being exploited in the wild - not just having exploit code written for it - is a highly relevant indicator of whether it can be exploited and whether it will be in the future. For example, it it certainly possible to imagine that as soon as exploit code is published, most organizations are able to implement simple and effective mitigations (changing firewall rules, conducting an easy update, etc.). Conversely, if exploitations are observed in the wild because mitigation is very challenging, it is reasonable to predict that that they will continue to be seen in the future.
Putting it into practice
Building a mature vulnerability management program solely on the EPSS would be challenging, mainly for two reasons:
It only applies to CVEs, which, as discussed, represent a minority of your total cyber risk surface.
It says nothing about the severity of exploiting an issue.
With that said, it certainly makes sense to include it as part of such a program, and in doing so, I would make a few recommendations.
Interpreting an EPSS reading can be slightly tricky, but to help in doing so, I did a quick analysis of data available. Creating a histogram of all EPSS scores (bucketed in intervals of .05 across the x-axis) existing as of February 25, 2022 revealed the below:
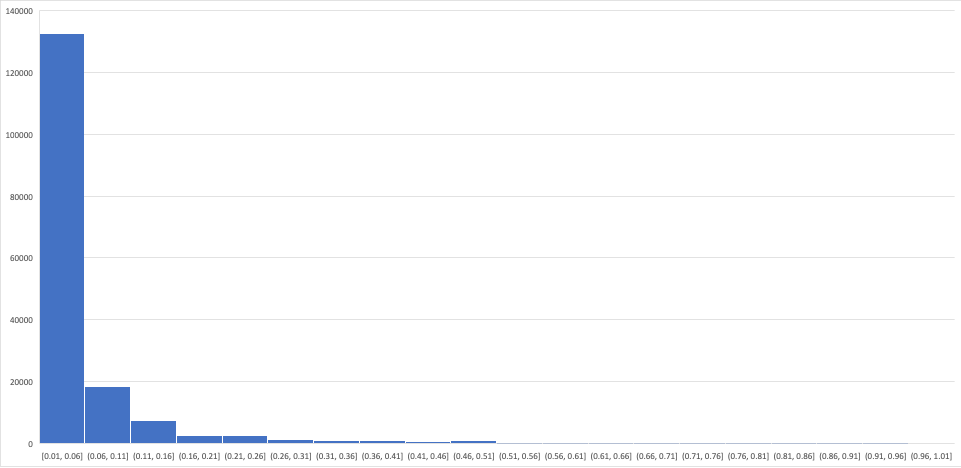
The bottom line here is that the overwhelming majority of CVEs 5% or less chance of being exploited in the next 30 days.
This, of course, does not mean they can all be safely ignored. A vulnerability with a 1% chance of exploitation in the next 30 days that could result in a…say…$575 million loss represents risk valued at $5.75 million a month and $69 million a year (assuming that the EPSS score holds steady over that year). Mitigating such a risk is worth hiring entire new teams of people or even acquiring whole companies. Conversely, if there is a 1% chance of exploitation of a vulnerability that results in a loss of $100 (e.g. from an annoying DoS attack that prevents one customer from making a purchase from an eCommerce site once a month), it represents a risk worth $1 a month and $12 a year (again assuming the EPSS holds steady). This is the type of risk that a company should probably accept.
Thus, understanding the underlying assets that can be impacted by exploitation of a vulnerability is crucial to determining the path to remediation. It is not possible to do so merely by looking at the EPSS.
If, however, you are like most organizations and are inundated by “highs and criticals” regularly and don’t have the resources to even determine the nature of the potentially impacted assets, it probably makes sense to further slice vulnerabilities of similar severity by the EPSS and then prioritize their remediation using that factor as a second dimension.
Finally, it is important to note that EPSS ratings are generated for a given CVE, not for a given application or service running a component with that CVE. The true likelihood of exploitation can thus be (much) higher or lower based on your given environment and the controls you have applied. For example, if exploiting a vulnerability relies on the victim changing the default configuration of an operating system, and you haven’t done that, then the likelihood of exploiting this vulnerability is functionally zero.
Conclusion
While the EPSS won’t necessarily give you a customized view of your specific risk picture given the widely varying environments, controls, and asset values of different organizations, it is certainly a great place to start if you don’t have any other data. Especially since security teams constantly need to grapple with huge volumes of CVEs (including those with an NVD CVSS of 7+), having a tool to prioritize these (at first glance) high severity issues in a more granular way can be a lifesaver.
With that said, and similarly to the CVSS, the EPSS by itself should not be used as a risk management tool. It can form one of the two key inputs (likelihood) to a risk calculation, but understanding the severity of exploiting a potential vulnerability is a second crucial input for evaluating the risk it poses.