
3rd (and greater) party code risk: managing known vulnerabilities
How to evaluate risk stemming from code you didn't write.


One vendor study suggests nearly 100% of all code bases contain a 3rd party component. While employing pre-written code reduces duplication of effort and greatly aids in development velocity, it brings with it a series of potentially grave risks. In addition to introducing unintentionally created – but exploitable – vulnerabilities into business-critical software, less than vigilant developers can even add malicious packages to their applications.
Even properly vetted external code can rely on otherwise unrelated 3rd party code, creating transitive dependencies and 4th party risk. Although organizations can only directly add or remove 3rd party code from their application, what I call 3rd and greater (>3rd) party code risk remains a major challenge for those developing and operating software.
Many publicly available sources of information regarding known vulnerabilities abound, most notably the National Institute of Standards and Technology's National Vulnerability Database (NVD) but also including the publishers of software themselves. Many companies and non-profit organizations also provide products – software composition analysis (SCA) and network vulnerability scanner tools – that can review >3rd party code for previously identified vulnerabilities. While using these sources of information is an improvement over blindly incorporating code of unknown provenance into your application, properly mitigating >3rd party code risk requires more than just using the right database or tool. Addressing this risk while still meeting rapidly shifting business requirements requires rigorous analysis, a comprehensive risk management framework, and consistent enforcement.
Scoping
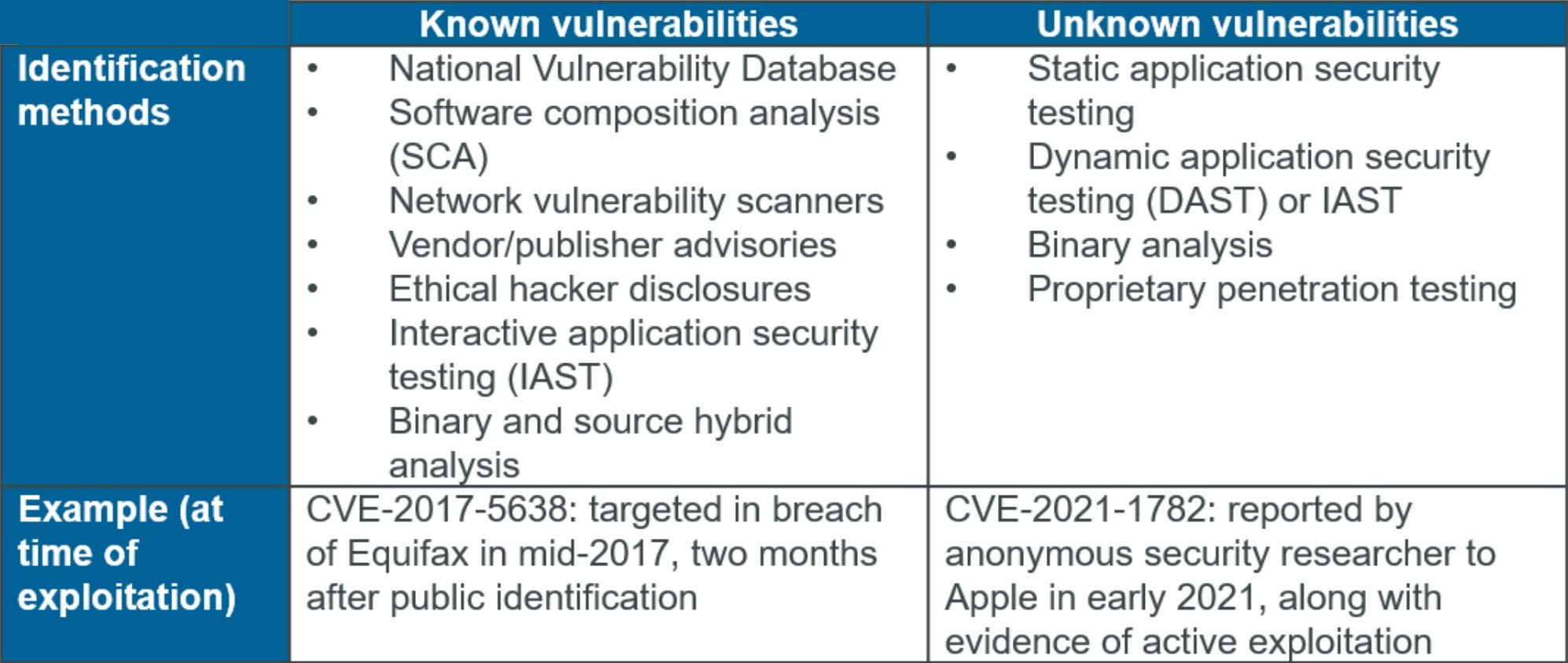
Although lines are increasingly difficult to draw with the rapid advancement of technology and the blurring of digital relationships between organizations, I will focus this particular article only on >3rd party code risk stemming from known vulnerabilities. By this I mean potential vectors through which an attacker could negatively impact the confidentiality, integrity, or availability of an organization’s data that are identifiable from public and certain proprietary commercial sources. Such sources include the NVD, traditional SCA tool databases, network vulnerability scanners, software publisher security bulletins, and ethical hacker disclosures. Methods such as binary and source hybrid analysis – in which a static analysis tool can evaluate source code calls to an external library in context – as well as interactive application security testing (IAST) – which can identify references to libraries with known vulnerabilities – can also highlight known vulnerabilities. In short, known vulnerabilities have (or should have) a unique common vulnerabilities and exposures (CVE) identifier.
My definition of known vulnerabilities would exclude the results of traditional static application security testing (SAST), dynamic application security testing (DAST), certain types of binary analysis, as well as any novel findings (e.g. not knowable from sources identified in the previous paragraph) from proprietary penetration testing an organization conducts or contracts an outside party to perform. Compared to known vulnerabilities, unknown vulnerabilities necessarily cannot have a CVE number, but will generally match the pattern of a common weakness enumeration (CWE), which describes a specific category of security vulnerabilities.
Limiting risk management policies and procedures to known vulnerabilities would leave a major gap in an organization’s security posture. To be clear, I do not advocate doing so. Some of the most dangerous advanced persistent threat actors make use of zero-day, or previously unknown (to the general public or industry) vulnerabilities. I feel it is reasonable to focus this particular discussion only on known vulnerabilities, however, based on the fact that some organizations do not even take appropriate action based on public information, occasionally with disastrous impacts. Obviously, even those that do can still fall prey to malicious actors sophisticated enough to identify previously unidentified software flaws. As identifying and mitigating >3rd party risk from unknown vulnerabilities warrants a discussion in and of itself, I will address it in a future article.
Challenges
Parties writing and updating >3rd party code can range from a single inexperienced hobbyist to a massive technology company with a huge budget and a highly skilled, dedicated team. These authors understandably write code of widely varying security and reliability. Although it is difficult to determine whether the reported explosion in vulnerabilities in such code is the result of better detection, deteriorating coding practices, or both, the fact is that publicly identified security bugs are rampant.
Additionally, abandoned libraries – which can serve as a chronically and increasingly worsening weak link in software using them – abound. Finally, a small number of open-source libraries are actually developed specifically for malicious purposes and are essentially malware themselves. By luring developers into using them, hackers can potentially trick a well-meaning party into building a backdoor into an application. While this might seem like an unlikely and extreme occurrence, unfortunately, that is not the case. The “Backstabber’s Knife Collection,” an aptly named study released in mid-2020, identified 174 malicious packages that had been available publicly for an average of 209 days before being reported.
Unfortunately, understanding of how to evaluate the true risk of using >3rd party code varies widely across information security professionals. For example, an organization might attempt to prioritize updating libraries using a publicly available metric – like the Common Vulnerability Scoring System (CVSS) rating in the NVD. Some industry research suggests that only 15-30% of vulnerabilities in >3rd party libraries are actually exploitable, however, and exploitability is highly dependent on the architecture of the application using the library. Thus, what might seem like a reasonable course of action – updating libraries based on the severity of flaws in them, as identified in a federal government database – could in fact be counterproductive and represent a waste of scarce engineering resources.
For example, the Ubuntu vulnerability CVE-2017-8283 has a CVSS score of 9.8 (out of 10.0) per the NVD and might seem like an appropriate top priority for remediation. Digging more deeply would reveal that it is impossible to exploit when the software is in its default configuration and that the publisher deems the vulnerability to be of “negligible” priority. Conversely, at first glance CVE-2017-16044 would appear to be a relatively lower priority, with a CVSS score of 7.5. Counterintuitively, this issue is present in a known malicious package and can allow a hostile cyber actor to hijack the victim’s environment variables. Thus, CVSS score is not dispositive as to the true threat to the organization. Although this is an extreme example, reporting of vulnerabilities in externally-written code has exploded and technology organizations are often overwhelmed with reports of potentially severe flaws, making effective prioritization even more important.
Furthermore, organizations often have gaps, overlaps, or both in their scanning coverage of >3rd party code. Many organizations package open-source programs such as operating systems (OS) in container images which they either operate themselves or distribute to customers. As of mid-2019, half of all those participating in an industry survey did not perform any sort of vulnerability scan of the OS layer of their Docker images. Similarly for code libraries, different tools have varying levels of effectiveness depending on the programming language in which a given library is written. In an attempt to cover such gaps, organizations apply multiple scanning tools to their code base, which can then generate a flood of redundant findings and exacerbate the aforementioned prioritization problem.
Solutions
The first thing any organization should do when evaluating >3rd party code risk is to assess the risk landscape holistically. Whether using the framework I recommend – creating a dichotomy between known and unknown vulnerabilities – or some other structure, it is important to ensure that your organization has a plan to identify and mitigate all relevant risk. The goal should be to ensure complete coverage of all possible threats by developing a mutually exclusive and completely exhaustive logical structure for analysis. As the distinction between software products and services blurs with the rapid digitization of every aspect of business, it is also important not to build a strategy around artificial stovepipes.
For example, a company may have different business units that fulfill varying functions and thus have different standard operating procedures or risk tolerances. From the customer – or hacker – perspective, however, these bureaucratic groupings are irrelevant. If stealing sensitive data or disrupting operations through vulnerable >3rd party code is possible, it makes no functional difference which internal group is responsible for it. Thus, it is important to ensure that any risk assessments or mitigations cover the entire potential attack surface for the data or processes that you are seeking to protect.
On a technological level, ensuring comprehensive coverage across the technology stack is also vital. This means determining what 3rd party libraries and applications the organization operates or packages with its products, and what languages they are written in. Such an investigation should include exploring (preferably through automated means) what is often a spider web of transitive dependencies. Once a full inventory is complete, then you should identify the appropriate scanning tools (e.g. SCA for development or network vulnerability scanner for operations) and/or alerting mechanisms (e.g. vendor security advisories) that can provide timely updates regarding vulnerabilities. This is often where organizations run awry, as they may accidentally exclude things like open-source stand-alone software from their tool coverage (or it might not be feasible to review), while not identifying an alternative source for vulnerability notifications. Establishing a central clearinghouse for this information and apportioning clear responsibility as to who is responsible for tracking issues to resolution are thus important early steps.
Furthermore, rather than blindly accepting the CVSS score of an identified issue as reported by a scanning tool or the NVD, an effective risk management policy must require an automated or manual technical analysis of the vulnerability in context. In most cases, if your proprietary code is not calling the method(s) in the 3rd party code impacted by the vulnerability, an attacker cannot exploit it. Any effective vulnerability management policy – which dictates the timelines for resolution of potential security bugs and flaws – must incorporate such analysis into its logic. To do otherwise would require your engineering organization to waste valuable time updating or replacing 3rd party code that poses no risk.
Once the total risk picture is clear, developing comprehensive but easily implemented procedures is the next step. Clear communication throughout the organization regarding the appropriate steps to select, vet, and gain approval for 3rd party code use, disseminated down to the individual engineer level, is necessary for ensuring compliance. Automating approval chains and enforcement of the aforementioned risk tolerances is possible using industry standard tools. I would strongly suggest using the same system in which engineers track normal development work and bugs – or one which can integrate with it – for managing approvals, technical analyses, and risk acceptances. A quick test with respect to the durability and simplicity of your procedures is to ask whether gaining approval requires emailing someone else and awaiting a response. If this is the case, the workflow is too manual and is prone to delay and failure. Facing business pressures to deliver software on time and on budget, engineers are likely to simply ignore such slow-moving processes.
Finally, developing clear metrics – which incentivize desirable behavior – for triaging and resolving identified issues in >3rd party code is critical towards understanding the effectiveness of an organization’s risk management program. Mean time to resolution of known vulnerabilities is one such measurement, although I would advise using the total time elapsed since public identification of the issue rather than an artificial metric like business days, about malicious actors do not care. With the appropriate metrics established and communicated, leaders can encourage competition amongst developers to see which individuals or teams achieve the best results. With appropriate safeguards and peer reviews in place to prevent hasty or erroneous diagnosis of vulnerabilities as “false positives,” achievement of certain metrics might even serve as an appropriate basis for compensation decisions.
Conclusion
The use of 3rd party code in modern applications is here to stay, and the ability to re-use work already done provides huge productivity benefits to organizations. Unfortunately, using components with known vulnerabilities remains one of the top ten risks facing technology organizations per the Open Web Application Security Project’s most recent list. Since the scope of the problem is so vast and so poorly understood, some enterprises simply ignore the accompanying risks. Others are hyper-focused on resolving specific issues based on inappropriate metrics, such as CVSS score as reported in the NVD, while remaining oblivious to other threats entirely. Developing a comprehensive risk management framework to address known vulnerabilities at all levels of the technology stack in an automated, repeatable, and rapid manner is the only appropriate response. By doing so, both the public and private sectors can better defend against the bevy of hackers who are quick to exploit attack vectors in >3rd party code.
I wrote this article on behalf of PTC when I served as a product manager leading cybersecurity strategy for the ThingWorx Industrial IoT Solutions Platform.